Using a Neural Network Codec Approximation Loss to Improve Source Separation Task Performance in Limited Capacity Networks
Ishwarya Ananthabhotla1, Sebastian Ewert2, Joseph Paradiso1
1. Summary
A growing need for on-device machine learning has lead to research efforts dedicated to light-weight, limited capacity neural networks. However, any approach to designing small-scale networks results in a tradeoff between model capacity and performance that must be optimized. In this work, we consider a psychoacoustically motivated objective function first presented in our prior work, and adapt it to two audio source separation tasks. We demonstrate an improvement in performance for small-scale networks via listening tests, characterize the behavior of the codec-emulating loss network more thoroughly, and quantify the relationship between the performance gain and model capacity. Our work suggests the potential for and deeper explorations in incorporating perceptual principles into objective functions for audio neural networks.
2. Training a Custom Loss Network
A lot of what we know about psychoacoustics, primarily the principle of frequency masking, is already built into audio codecs. So for any supervised neural network task involving audio, it would make sense to compare both a sample predicted by the network and the corresponding ground truth sample in the coded domain, so we only penalize the network for perceptually relevant components of the signal. But open-source codec implementations are not differentiable approximations -- how can we still take advantage of them? We first train a convolutional U-Network to learn a 16kbps MP3 encoding, using pairs of lossless and coded music samples. We do this in both the time domain and magnitude spectrogram domain, though the latter works better.
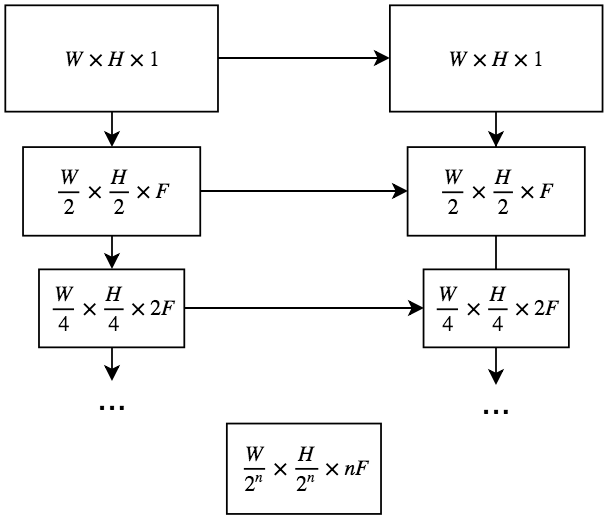

3. Improving Performance for Small Scale Networks
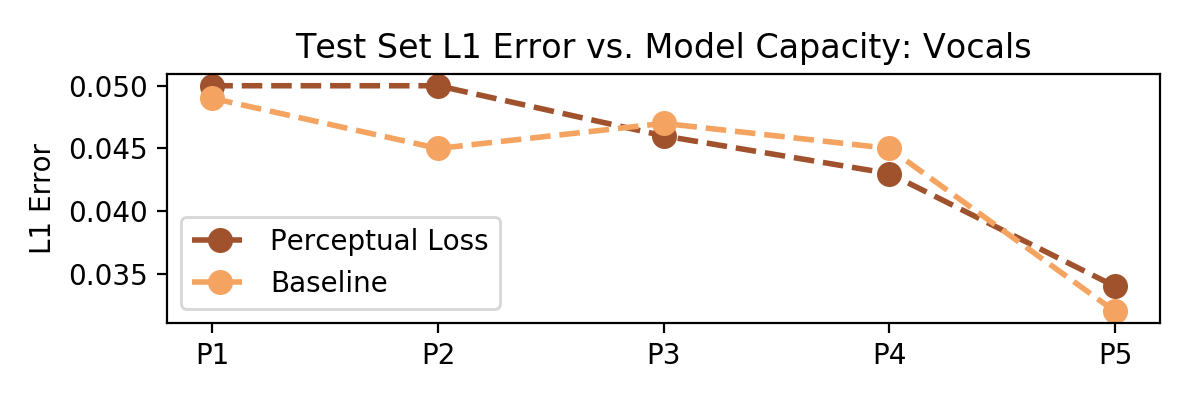
Let's consider two audio source separation tasks -- a speech denoising task, and a vocal separation task. Let's also consider five U-Network architectures with increasing capacity (measured in number of trainable parameters) designed to learn these tasks from pairs of mixture and source magnitude spectrograms. We show that, for smaller networks, using the perceptual loss improves performance over an l1 baseline; for larger networks, performance converges to the baseline. Cool!
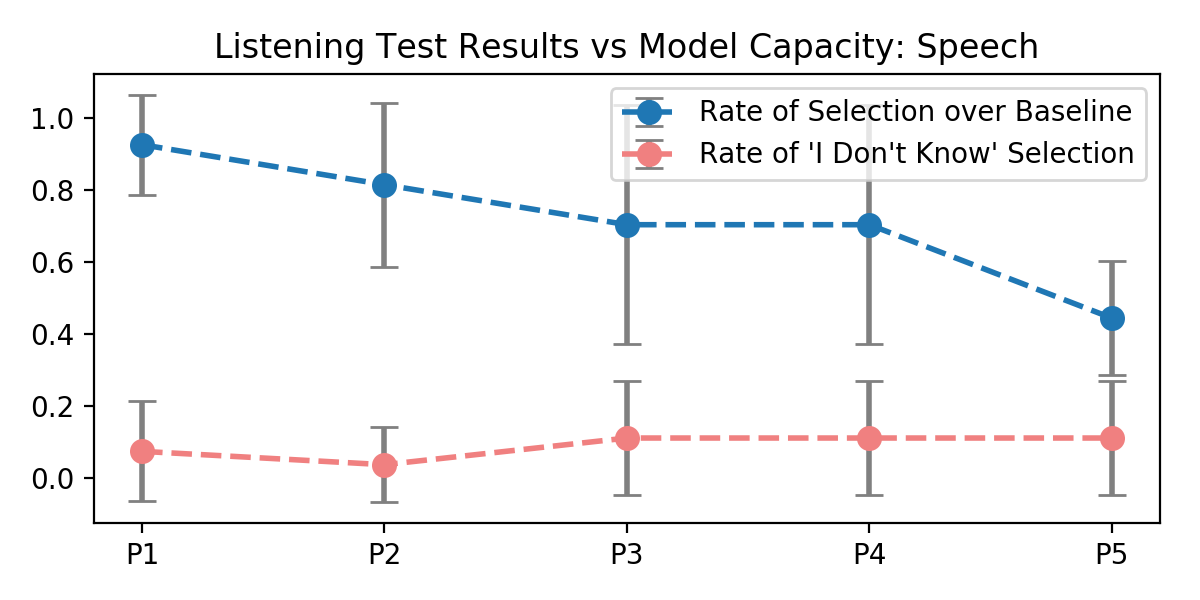
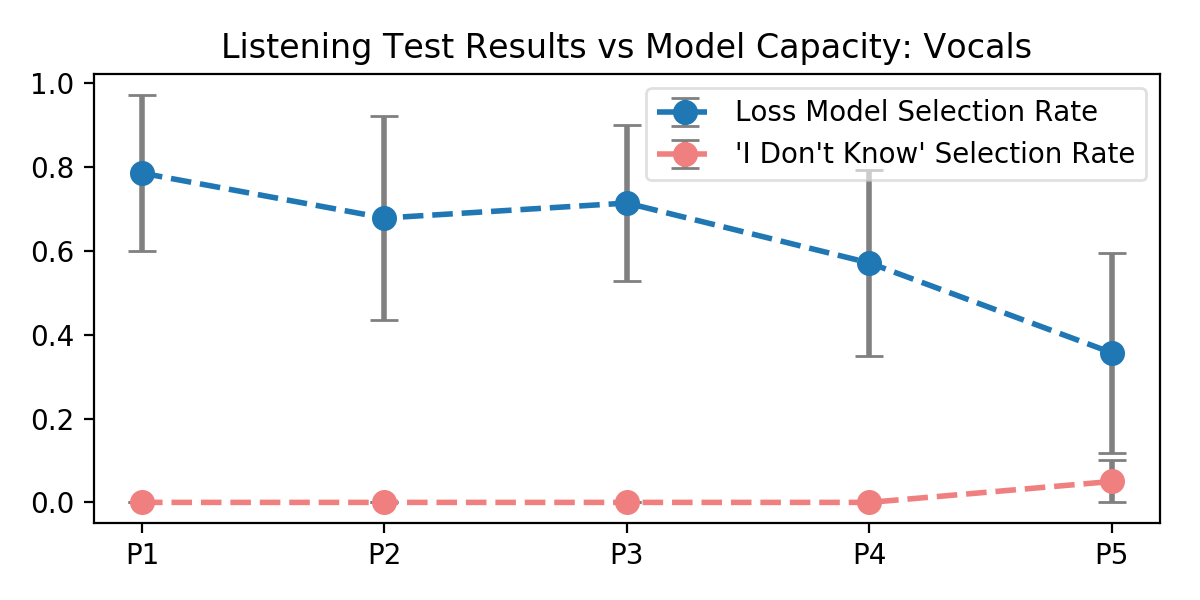
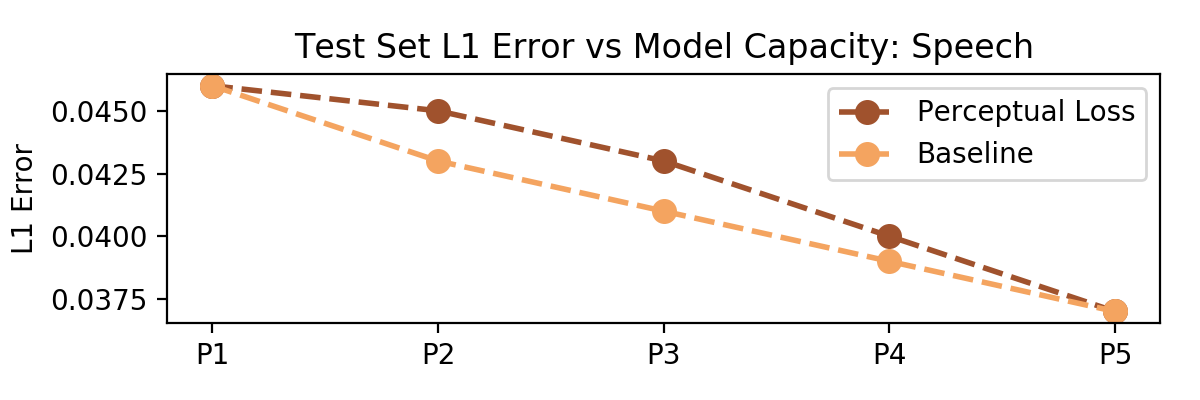
It also turns out the l1 loss measured as a metric in the perceptual loss case pretty tightly follows or underperforms the baseline case; that suggests that loss network is not just serving as a regularizing, but is in fact forcing the network to optimize for different regions of the spectrum.
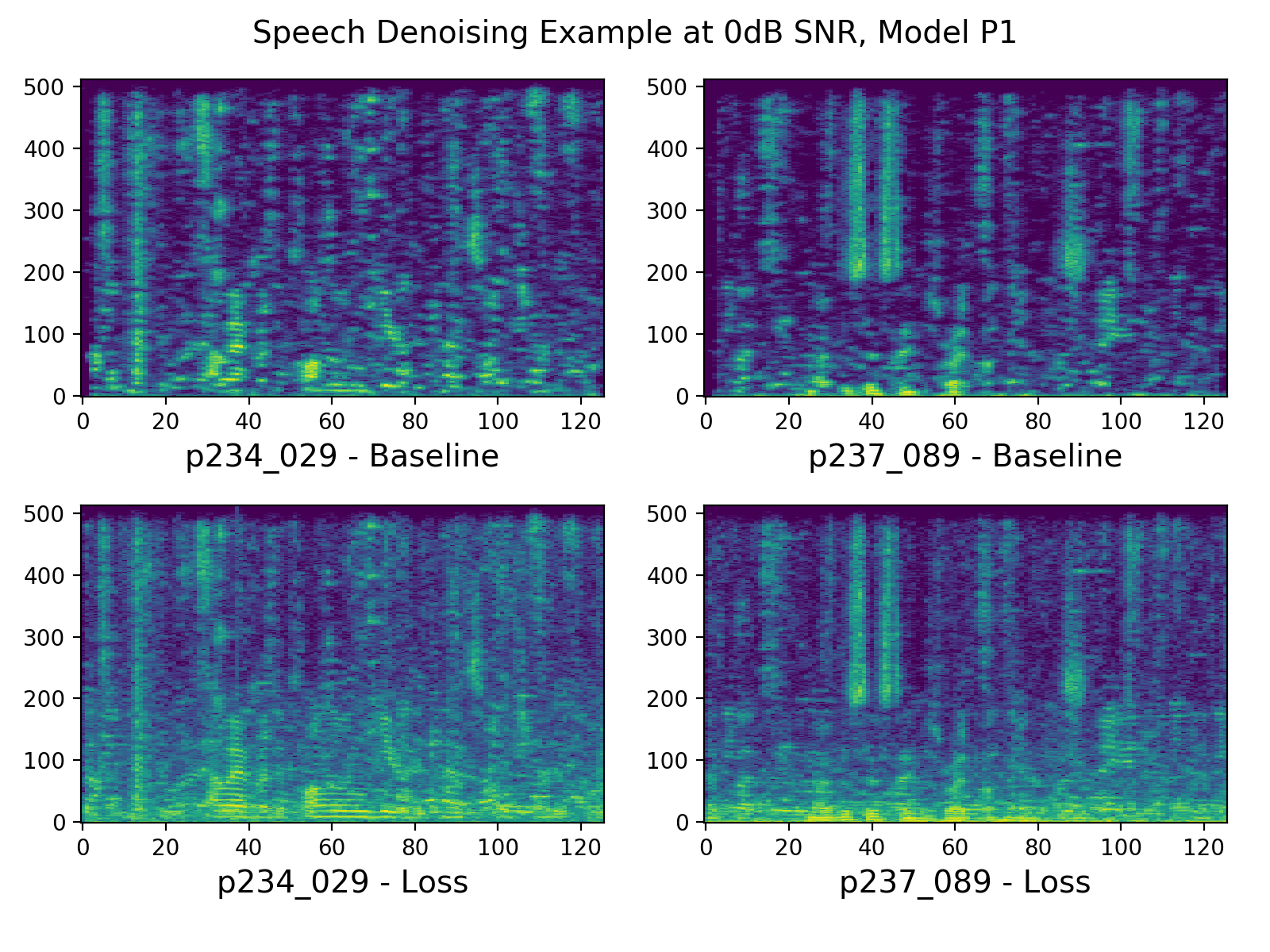
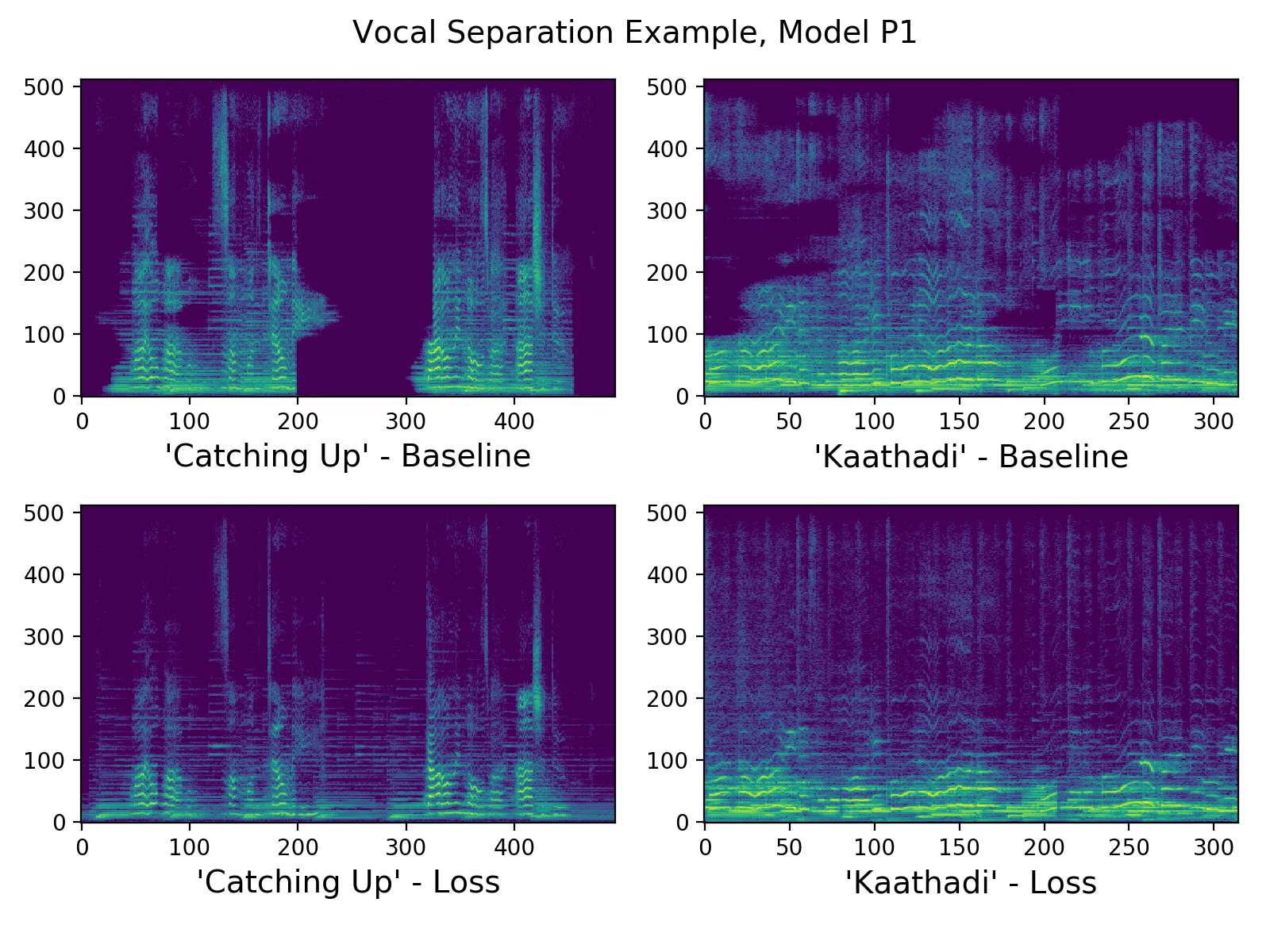
Here's what the resulting spectrograms look like for the speech and music tasks. It appears that in the loss case, the spectrogram is actually "noisier", and we might assume that that is because the network is allowed to simply ignore some regions of the spectrum.
4. Audio Samples Comparing Baseline and Loss at Different Model Capacities
| Speech Denoising Sample 1 - Baseline | Speech Denoising Sample 1 - Loss | Speech Denoising Sample 2 - Baseline | Speech Denoising Sample 2 - Loss | |
|---|---|---|---|---|
| P1 | ||||
| P2 | ||||
| P3 | ||||
| P4 | ||||
| P5 |
| Vocal Separation Sample 1 - Baseline | Vocal Separation Sample 1 - Loss | Vocal Separation Sample 2 - Baseline | Vocal Separation Sample 2 - Loss | |
|---|---|---|---|---|
| P1 | ||||
| P2 | ||||
| P3 | ||||
| P4 | ||||
| P5 |